计网学习笔记应用层篇2-DNS
前言
上一篇写了HTTP的学习笔记,但是其实运用HTTP去实现DNS也是一种技巧,可以解决很多问题,想在这篇笔记里记录下关于DNS的知识点以及对其的思考
DNS
DNS提供的服务
- 域名向IP地址的翻译
- 主机别名:主机别名比规范名更容易记忆,应用程序可以调用DNS来获取主机别名对应的规范主机名以及主机的IP地址
- 邮件服务器别名:和主机别名相同
- 负载均衡:对于一些繁忙的Web服务器,站点被分布在多台服务器上,每台服务器均运行在不同的端系统,有不同的IP地址;当client对映射到IP集合的域名发出一个DNS请求,服务器会以整个IP地址集合进行响应,但每次响应中训话这些IP次序
DNS工作原理
- 向网络中发送DNS请求报文,DNS请求和响应报文都使用UDP数据报经端口53发送
- 采用分布式层次数据库
[Q1:为什么DNS使用UDP而不是TCP?]
- 基于UDP的基于UDP的DNS协议只要一个请求、一个应答
- DNS数据包不是那种大数据包,所以使用UDP不需要考虑分包,如果丢包那么就是全部丢包,如果收到了数据,那就是收到了全部数据!所以只需要考虑丢包的情况,那就算是丢包了,重新请求一次就好了。而且DNS的报文允许填入序号字段,对于请求报文和其对应的应答报文,这个字段是相同的,通过它可以区分DNS应答是对应的哪个请求
- DNS通常是基于UDP的,但当数据长度大于512字节的时候,为了保证传输质量,就会使用基于TCP的实现方式
- 所以我们熟知的nslookup就是先使用基于UDP,再基于TCP的DNS查询
[Q2:为什么DNS要采用分布式层次数据库,而不是单体结构?]
- 单点故障:如果这个DNS服务器崩溃了,整个因特网就会随之瘫痪
- 通信容量:单个DNS服务器不得不处理所有的DNS查询(用于为上亿台主机产生的所有HTTP请求报文和电子邮件报文服务)
- 远距离的集中式数据库:单个DNS服务器不可能邻近所有查询客户,会导致查询过程中有可能需要经过低速和拥塞的链路,导致严重的时延
- 维护:单个DNS服务器将不得不为所有的因特网主机保留记录,导致中央数据库非常庞大,而且还需要为每个新添加的主机频繁更新
分布式、层次数据库
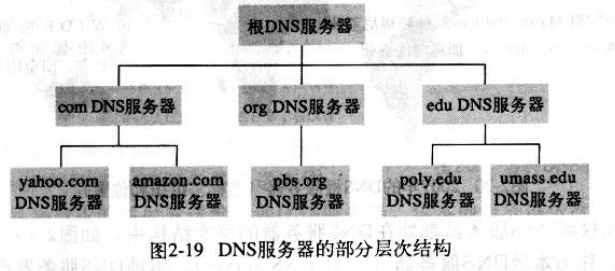
在DNS的层次化组织中大致有三类DNS服务器
- 根DNS服务器:因特网上有13台根DNS服务器,每台根服务器提供单体服务
- 顶级域DNS服务器:负责顶级域名如com、org、net、edu、gov,以及所有国家的顶级域名如uk、fr、ca、jp
- 权威DNS服务器:组织结构的DNS服务器收录了各自DNS记录
本地DNS服务器
- 每个ISP都有一台本地DNS服务器,当主机与ISP相连时,该ISP提供一台主机的IP
- 临近客户机
- 起代理作用,将请求转发到DNS服务层次结构中
递归查询与迭代查询

递归查询:客户端只发一次请求,要求对方给出最终结果
迭代查询:客户端发出一次请求,对方如果没有授权回答,它就会返回一个能解答这个查询的其它名称服务器列表,客户端会再向返回的列表中发出请求,直到找到最终负责所查域名的名称服务器,从它得到最终结果
客户端—本地dns服务端:这部分属于递归查询
本地DNS服务端—DNS层次服务结构:这部分属于迭代查询
递归查询时,返回的结果只有两种:查询成功或查询失败
DNS缓存
- 浏览器DNS缓存:浏览器DNS缓存的时间跟DNS服务器返回的TTL值无关,浏览器在获取网站域名的实际IP地址后会对其IP进行缓存,减少网络请求的损耗。每种浏览器都有一个固定的DNS缓存时间,其中Chrome的过期时间是1分钟,在这个期限内不会重新请求DNS
- Android DNS缓存:
- 框架层 java.net.InetAddress类缓存
- 虚拟机层DNS缓存
- 执行策略:先从框架层缓存中查找,如果没有找到,再到虚拟机层查找。缓存命中,则直接返回缓存IP 缓存时间为2s
- OS DNS缓存:本地host文件DNS缓存
HTTPDNS
[Q:为什么要提出HTTPDNS这种技术?]
DNS域名解析会存在劫持的风险:大多数的网络请求第一步就是DNS过程,经过1-RTT的时间将域名转化为IP地址,然后再去发起请求。DNS过程不仅耗时不稳定(3G下200ms,4G下100ms),而且可能解析失败,甚至被劫持,将用户导入到了错误的IP地址。如果攻击者自己做一个仿冒的网站,劫持你的DNS并将IP转到这个假网站上,可能会造成很大的用户数据泄漏和公司品牌损失
而HTTPDNS这种技术的提出就是为了通过HTTP协议搭建自己的DNS解析服务,并且在全国多地部署相关的服务器提供安全解析DNS服务
基本原理
- 通过发起Http请求到HttpDNS服务器,获取某个域名对应的可用IP列表
- IP列表可以根据用户当前的地点进行返回,而且默认会进行IP测速,按速度排序
- 伴随这IP列表,服务器还会下发一个缓存有效时间 TTL,从而将IP列表缓存在本地,并在即将过期前及时去更新IP列表,保证每次网络请求都可以使用当前最优的IP地址
内置IP列表+自动测速
由于HTTPDNS消耗的成本相对更高,一些轻量级的做法就是内置IP列表+自动测速
基本原理:
在apk打包时会内置一份IP列表进去。当App启动时,这些IP的权重相同,此时会随机从里面获取IP来使用。但是这有个问题,对不同地区的用户而言,最优IP肯定是不同的。比如对于上海的用户而言,上海区服务器的IP肯定是最快的,而对于深圳的用户而言,华南区IP才是最快的。因此,在App运行过程中,我们会通过依次对IP列表逐个进行Ping测速,根据测速结果动态变更IP的权重,然后提供给网络连接使用
IP列表的缓存更新策略
[Q:为什么需要考虑缓存更新策略?]
移动网络是在不断变化的。最常见的场景,比如我们从Wi-Fi切换到了4G,获取进入电梯后从4G降级成3G,或者我们从A Wi-Fi换到了B Wi-Fi,这都意味着我们的网络链路变更了。那么,之前缓存的IP列表不一定仍可用或者不一定是最优
更新方式:
- 定时器监听HttpDNS返回的TTL过期时间。当IP列表即将过期前,发起请求获取下一轮的IP列表并进行更新
- 监控网络连接状态,网络链路切换,比如Wi-Fi/3G/4G转换,如果是Wi-Fi,还可以监控SSID信息变更(针对不同的Wi-Fi热点),及时触发IP列表刷新;在异步更新过程中,可以仍然使用旧缓存IP提供服务
- 配置中心下发,这种有时会用在服务器分流,比如某台服务器压力过大,可以通过配置中心系统下发新的IP列表给客户端访问
- IP列表缓存应该对不同网络类型、网络标识有对应的一份缓存,可以使用网络类型(3G、4G、Wi-Fi等)+网络标识(SSID、ispCode等)作为缓存Key,当网络切换时,使用Key去查询缓存
- 这些缓存可以持久化到多个文件,以Key作为文件名,同时可以基于当前网络状态,缓存一份IP列表到内存供使用,当网络状态变化,则刷新内存缓存
IP列表可用性兜底策略
[Q:为什么需要相应的兜底策略?]
如果HttpDNS服务器出现故障呢,或者首次打开App,HttpDNS还没有完成,或者大面积DNS劫持等,如果获取不到IP列表,需要一定的兜底策略去保证用户的网络请求不受影响
具体兜底策略的优先级排序:
- HttpDNS IP:即大厂自建的HttpDNS服务获取动态IP
- DNS IP:即常规Local DNS获取IP
- Auth IP:通过配置下发的动态保底IP列表
- Hardcode IP:本地写死的保底IP列表
如果发生故障,导致这两个方案都不可用,比如大面积DNS劫持之类的,这时客户端必须能够自动降级到静态兜底IP,保证网络服务可用
[Q:兜底策略存在什么问题?]
静态兜底IP对应服务器访问量可能会突然暴增,如果峰值太高可能造成更大的危害如雪崩。因此,除了内置静态兜底IP,还需要为客户端提供一个可通过配置动态下发的兜底IP列表,可以做到负载均衡,将流量分散到不同机器上。而且这些静态IP贵精不贵多,并且要有高可用的后台服务保证,作为全局网络服务的兜底
针对弱网的多IP复合连接测速
[Q:为什么需要设计针对弱网的多IP复合连接测速?]
A:用户处于弱网状态下,IP连接成功率很低,需要采取一些措施进复合测速处理
针对弱网一般有两种方式:
- 串行连接:先连接第一个IP,直到发生了超时,再去对第二个IP建连
- 并行连接:同时对多个IP建立连接,哪个连成功了就用哪个
[Q:串行连接有什么弊端?]
串行连接可能需要很长时间的试错,才能找到可用的IP,而且这里还取决于如何选择超时时间,如果超时时间较长,则需要很长时间才能找到可用IP;如果很短,则可能会漏掉一些相对优质的IP,不断去尝试新IP,恶性循环
[Q:并行连接有什么弊端?]
并行连接则会对服务端造成极大的连接负载压力和一定程度的浪费,对于电量也有一定程度开销
[Q:如何解决这些问题?]
采用Mars里的复合连接策略学习:
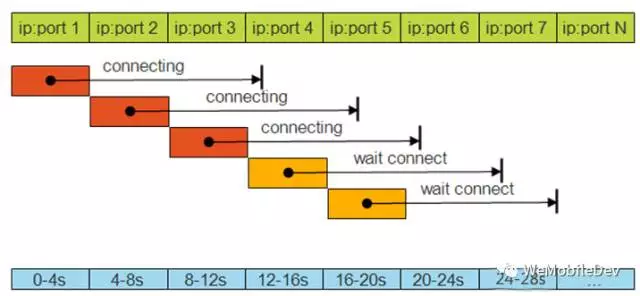
在弱网状态下,依次发起对5组IP+Port的连接,10s作为超时时间。当前一个连接发起了4s钟还未成功,则立即发起下一个连接,以此类推。当其中有一个连接建立成功,则立即停止其他连接。这样的方式可以兼备串行连接和并行连接的优势:较快找到可用IP,同时对于服务器不会造成过大的连接压力。至于这个超时时间10s,则可以通过上报数据来动态统计,找到一个合理的超时时间
感谢: