深入MultiDex优化
回顾
在上一篇文章Tinker资源热修复中的压缩美学中我们通过对TinkerZipFile、TinkerZipEntry、TinkerZipOutputStream的源码进行学习,进一步加深对zip文件结构的了解,以及实际地看到了Tinker的作者是如何把自己对zip文件的理解应用在项目中的
而本文的目的是想深入MultiDex优化,网上其实关于MultiDex的原理与优化其实有不少的好文,而网上主流的两种MultiDex的优化方式为:
- 子线程intsall:直接在闪屏页开启子线程执行MultiDex的逻辑,让MultiDex不再影响冷启动速度,但是这个方案需要把闪屏页中用到的类放在主dex中,不然就会出现Class Not Found的问题,即便gradle有对外提供主dex的指定方式,但是由于一些第三方库中存在的ContentProvider,这套方案依然是相当难维护
- 今日头条方案:独立的loading进程执行intsall,用一个临时文件作为MultiDex是否加载完的条件,加载完后主进程再进行一次有缓存的MultiDex.install操作即可
综述上面的两种方案,实际上优化的并不是MultiDex的加载时间,而是项目中需要执行MultiDex时,优化了用户到达第一个可操作界面的时间
但是有没有方法能够真真正正地去减少MultiDex加载的时间呢?谈优化还是得先从性能瓶颈开始!
MultiDex的主要性能瓶颈其实是在两个地方:
- 首次加载需要花费的解压和压缩的耗时
- dexopt过程产生的耗时
本文将针对这两个问题,分别聊一聊怎么解决
对MultiDex中解压耗时的优化
MultiDexExtractor-> performExtractions
private List<ExtractedDex> performExtractions() throws IOException {
final String extractedFilePrefix = sourceApk.getName() + EXTRACTED_NAME_EXT;
// It is safe to fully clear the dex dir because we own the file lock so no other process is
// extracting or running optimizing dexopt. It may cause crash of already running
// applications if for whatever reason we end up extracting again over a valid extraction.
clearDexDir();
List<ExtractedDex> files = new ArrayList<ExtractedDex>();
final ZipFile apk = new ZipFile(sourceApk);
try {
int secondaryNumber = 2;
ZipEntry dexFile = apk.getEntry(DEX_PREFIX + secondaryNumber + ".dex");
while (dexFile != null) {
String fileName = extractedFilePrefix + secondaryNumber + ".zip";
ExtractedDex extractedFile = new ExtractedDex(dexDir, fileName);
files.add(extractedFile);
Log.i(TAG, "Extraction is needed for file " + extractedFile);
int numAttempts = 0;
boolean isExtractionSuccessful = false;
while (numAttempts < MAX_EXTRACT_ATTEMPTS && !isExtractionSuccessful) {
numAttempts++;
// Create a zip file (extractedFile) containing only the secondary dex file
// (dexFile) from the apk.
extract(apk, dexFile, extractedFile, extractedFilePrefix);
// Read zip crc of extracted dex
try {
extractedFile.crc = getZipCrc(extractedFile);
isExtractionSuccessful = true;
} catch (IOException e) {
isExtractionSuccessful = false;
Log.w(TAG, "Failed to read crc from " + extractedFile.getAbsolutePath(), e);
}
// Log size and crc of the extracted zip file
// ......
}
// ......
secondaryNumber++;
dexFile = apk.getEntry(DEX_PREFIX + secondaryNumber + DEX_SUFFIX);
}
} finally {
try {
apk.close();
} catch (IOException e) {
Log.w(TAG, "Failed to close resource", e);
}
}
return files;
}
先走到MultiDex过程中MultiDexExtractor对文件的获取过程,这里会从apk中解压出class2.dex…classN.dex,然后转调extract完成文件操作
MultiDexExtractor-> extract
private static void extract(ZipFile apk, ZipEntry dexFile, File extractTo,
String extractedFilePrefix) throws IOException, FileNotFoundException {
InputStream in = apk.getInputStream(dexFile);
ZipOutputStream out = null;
// Temp files must not start with extractedFilePrefix to get cleaned up in prepareDexDir()
File tmp = File.createTempFile("tmp-" + extractedFilePrefix, ".zip",
extractTo.getParentFile());
Log.i(TAG, "Extracting " + tmp.getPath());
try {
out = new ZipOutputStream(new BufferedOutputStream(new FileOutputStream(tmp)));
try {
ZipEntry classesDex = new ZipEntry(dexFile);
// keep zip entry time since it is the criteria used by Dalvik
classesDex.setTime(dexFile.getTime());
out.putNextEntry(classesDex);
byte[] buffer = new byte[BUFFER_SIZE];
int length = in.read(buffer);
while (length != -1) {
out.write(buffer, 0, length);
length = in.read(buffer);
}
out.closeEntry();
} finally {
out.close();
}
if (!tmp.setReadOnly()) {
throw new IOException("Failed to mark readonly \"" + tmp.getAbsolutePath() +
"\" (tmp of \"" + extractTo.getAbsolutePath() + "\")");
}
Log.i(TAG, "Renaming to " + extractTo.getPath());
if (!tmp.renameTo(extractTo)) {
throw new IOException("Failed to rename \"" + tmp.getAbsolutePath() +
"\" to \"" + extractTo.getAbsolutePath() + "\"");
}
} finally {
closeQuietly(in);
tmp.delete(); // return status ignored
}
}
这里会构建一个tmp-classN.zip的临时zip文件,然后把刚刚从apk中解压出来的classN.dex通过ZipOutputStream再次压缩成tmp-classN.zip中,这里构建临时文件再写入是一种比较常见的做法,为的是避免源文件收到干扰
而实际上我们可以看到MultiDex过程中会把apk中的dex解压出来,再重新压缩成zip,真的有必要这样做吗?
暂时没有从源码以及注释中确认这个答案,而对于这个问题,网上有两种声音:
- Android系统低版本并不支持对dex文件直接加载
- Android这种做法可能为了减少存储空间的占用
而其实现在大部分的应用,包括我在学校团队做的项目,其实也只会兼容到Android4.4版本了,所以实际上MultiDex其实切切实实地成了需要兼容到Android4.4的应用,在启动速度优化方面的大户了
而解决这个多余的解压重压缩的过程的解决方案也并非很难,因为已经有前辈帮我了写好了这套工具了,那就是Tinker,因此我们只需要对上述MultiDexExtractor中的两个方法进行改造就可以了
MultiDexExtractor-> performExtractions
private List<ExtractedDex> performExtractions() throws IOException {
final String extractedFilePrefix = sourceApk.getName() + EXTRACTED_NAME_EXT;
// It is safe to fully clear the dex dir because we own the file lock so no other process is
// extracting or running optimizing dexopt. It may cause crash of already running
// applications if for whatever reason we end up extracting again over a valid extraction.
clearDexDir();
List<ExtractedDex> files = new ArrayList<ExtractedDex>();
final TinkerZipFile apk = new TinkerZipFile(sourceApk);
try {
int secondaryNumber = 2;
TinkerZipEntry dexFile = apk.getEntry(DEX_PREFIX + secondaryNumber + DEX_SUFFIX);
while (dexFile != null) {
String fileName = extractedFilePrefix + secondaryNumber + EXTRACTED_SUFFIX;
ExtractedDex extractedFile = new ExtractedDex(dexDir, fileName);
files.add(extractedFile);
Log.i(TAG, "Extraction is needed for file " + extractedFile);
int numAttempts = 0;
boolean isExtractionSuccessful = false;
while (numAttempts < MAX_EXTRACT_ATTEMPTS && !isExtractionSuccessful) {
numAttempts++;
// Create a zip file (extractedFile) containing only the secondary dex file
// (dexFile) from the apk.
extract(apk, dexFile, extractedFile, extractedFilePrefix);
// Read zip crc of extracted dex
try {
extractedFile.crc = getZipCrc(extractedFile);
isExtractionSuccessful = true;
} catch (IOException e) {
isExtractionSuccessful = false;
Log.w(TAG, "Failed to read crc from " + extractedFile.getAbsolutePath(), e);
}
// Log size and crc of the extracted zip file
Log.i(TAG, "Extraction " + (isExtractionSuccessful ? "succeeded" : "failed")
+ " '" + extractedFile.getAbsolutePath() + "': length "
+ extractedFile.length() + " - crc: " + extractedFile.crc);
if (!isExtractionSuccessful) {
// Delete the extracted file
extractedFile.delete();
if (extractedFile.exists()) {
Log.w(TAG, "Failed to delete corrupted secondary dex '" +
extractedFile.getPath() + "'");
}
}
}
if (!isExtractionSuccessful) {
throw new IOException("Could not create zip file " +
extractedFile.getAbsolutePath() + " for secondary dex (" +
secondaryNumber + ")");
}
secondaryNumber++;
dexFile = apk.getEntry(DEX_PREFIX + secondaryNumber + DEX_SUFFIX);
}
} finally {
try {
apk.close();
} catch (IOException e) {
Log.w(TAG, "Failed to close resource", e);
}
}
return files;
}
把原本的ZipFile、ZipEntry、ZipOutputStream替换成Tinker中的实现就可以避免这次无意义的压缩了,而实际上我们还需要关注一个getZipCrc这个方法,在这个方法里也会像TinkerZipFile对ZipFile打开一个RandomAccessFile然后去获取Crc的值,而其实我们把这个逻辑加在TinkerZipUtil里面就好,这样就没必要再多创建一个RandomAccessFile了
MultiDexExtactor-> extract
private static void extract(TinkerZipFile apk, TinkerZipEntry dexFile, File extractTo,
String extractedFilePrefix) throws IOException, FileNotFoundException {
// Temp files must not start with extractedFilePrefix to get cleaned up in prepareDexDir()
File tmp = File.createTempFile("tmp-" + extractedFilePrefix, EXTRACTED_SUFFIX,
extractTo.getParentFile());
Log.i(TAG, "Extracting " + tmp.getPath());
try {
TinkerZipOutputStream out = new TinkerZipOutputStream(new BufferedOutputStream(new FileOutputStream(tmp)));
TinkerZipUtil.extractTinkerEntry(apk, dexFile, out);
out.flush();
out.close();
if (!tmp.setReadOnly()) {
throw new IOException("Failed to mark readonly \"" + tmp.getAbsolutePath() +
"\" (tmp of \"" + extractTo.getAbsolutePath() + "\")");
}
Log.i(TAG, "Renaming to " + extractTo.getPath());
if (!tmp.renameTo(extractTo)) {
throw new IOException("Failed to rename \"" + tmp.getAbsolutePath() +
"\" to \"" + extractTo.getAbsolutePath() + "\"");
}
} finally {
tmp.delete(); // return status ignored
}
}
对这两个方法的修改只是引入Tinker中对Zip文件的处理,然后把原生的api替换上去就可以了
一顿操作猛如虎,心情焦急、迫不及待地想测试一下优化率达到了多少,但是没想到居然Crash了
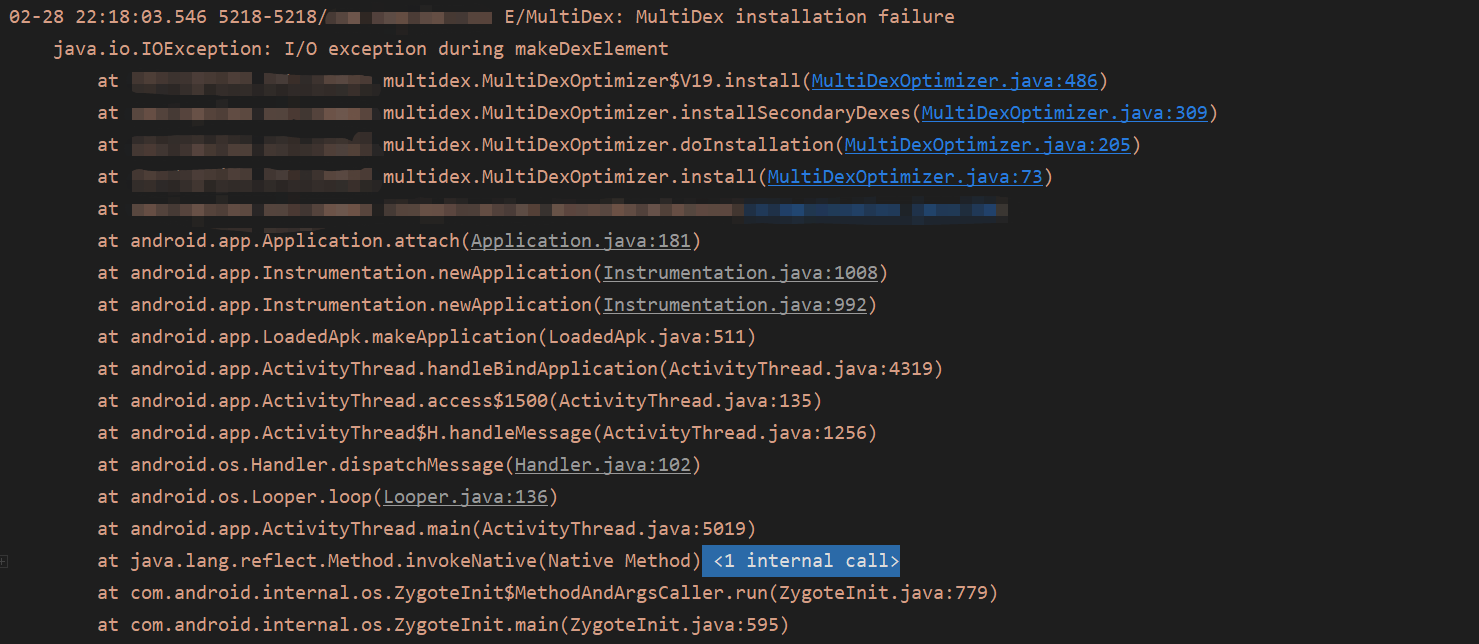
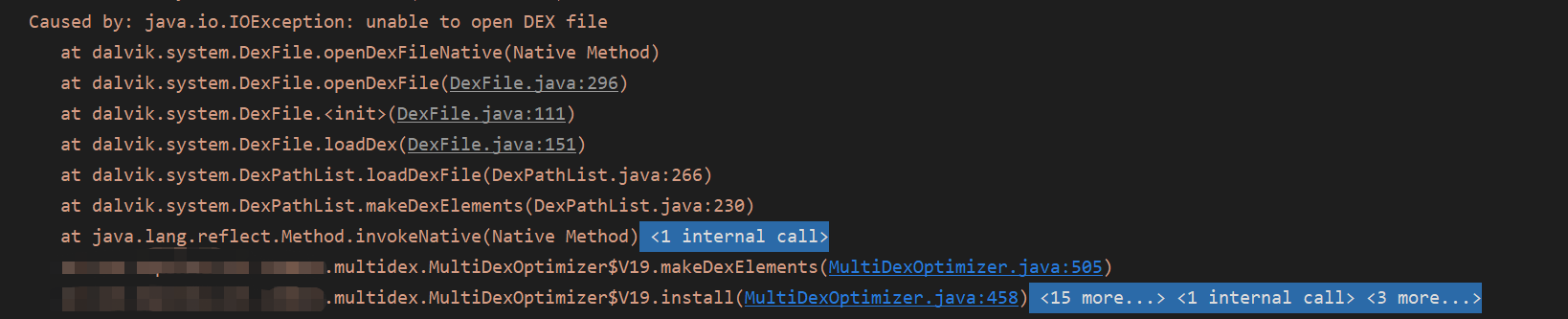
于是乎我们先找到出现Crash的地方然后一探究竟
MultiDexOptimizer.V19-> install
static void install(ClassLoader loader,
List<? extends File> additionalClassPathEntries,
File optimizedDirectory)
throws IllegalArgumentException, IllegalAccessException,
NoSuchFieldException, InvocationTargetException, NoSuchMethodException,
IOException {
/* The patched class loader is expected to be a descendant of
* dalvik.system.BaseDexClassLoader. We modify its
* dalvik.system.DexPathList pathList field to append additional DEX
* file entries.
*/
Field pathListField = findField(loader, "pathList");
Object dexPathList = pathListField.get(loader);
ArrayList<IOException> suppressedExceptions = new ArrayList<IOException>();
expandFieldArray(dexPathList, "dexElements", makeDexElements(dexPathList,
new ArrayList<File>(additionalClassPathEntries), optimizedDirectory,
suppressedExceptions));
if (suppressedExceptions.size() > 0) {
for (IOException e : suppressedExceptions) {
Log.w(TAG, "Exception in makeDexElement", e);
}
Field suppressedExceptionsField =
findField(dexPathList, "dexElementsSuppressedExceptions");
IOException[] dexElementsSuppressedExceptions =
(IOException[]) suppressedExceptionsField.get(dexPathList);
if (dexElementsSuppressedExceptions == null) {
dexElementsSuppressedExceptions =
suppressedExceptions.toArray(
new IOException[suppressedExceptions.size()]);
} else {
IOException[] combined =
new IOException[suppressedExceptions.size() +
dexElementsSuppressedExceptions.length];
suppressedExceptions.toArray(combined);
System.arraycopy(dexElementsSuppressedExceptions, 0, combined,
suppressedExceptions.size(), dexElementsSuppressedExceptions.length);
dexElementsSuppressedExceptions = combined;
}
suppressedExceptionsField.set(dexPathList, dexElementsSuppressedExceptions);
// Crash点
IOException exception = new IOException("I/O exception during makeDexElement");
exception.initCause(suppressedExceptions.get(0));
throw exception;
}
}
实际上当我们通过一系列的步骤拿到classN.dex的时候,还会反射调用DexPathList的makeDexElement方法进行zip文件的解压,然后fork一个进程去执行dexopt操作,而由于是反射调用的,所以才需要把一个IOException传递进去,让外界也可以感知到这个过程中异常的产生
而现在问题就比较难受,因为问题是出现makeDexElement中,而且实际上zip的解压以及dexopt的操作都是在native层去做的,我们解决这个问题最直接方法肯定是从源码中找到Crash产生的点,然后对我们的代码进行修改,但是请先不要急,我们其实可以先活用一波google工程师给我们提供的Log日志
02-28 23:00:11.324 5409-5409/? I/dalvikvm: Zip is good, but no classes.dex inside, and no valid .odex file in the same directory
02-28 23:00:11.334 5409-5409/? I/dalvikvm: Zip is good, but no classes.dex inside, and no valid .odex file in the same directory
可以看到其实实际上这个Crash的产生原因是因为,在把extract操作更换成TinkerZipUtil的实现后,我忽略去指定ZipEntry的的name了,而系统层面是通过classes.dex的这个name找到zip文件中对应的ZipEntry的,所以就gg了,所以实际上只要在创建TinkerZipEntry的时候指定它的name为classes.dex就不会有问题了
过滤掉了这次无意义的压缩过程,能达到多少的优化呢?下面我将用我们的项目执行一次测试
// 优化前
02-28 23:21:41.238 6157-6157/packageName E/multiDex: 2395
// 优化后
02-28 23:27:29.073 6760-6760/packageName E/multiDex: 1278
从实际的数据测试来看,其实去除这次无意义的解压和重压缩,可以给MultiDex的执行速度带来大约47%的时间优化,还是相当可观的
对dexopt过程产生的耗时的优化
对于dexopt过程产生的耗时的优化,其实业界里也有现成的实现与方案,在apk包体积优化的学习过程中,我了解到了Facebook对于Dex压缩所做的努力,Facebook App的classes.dex实际上只是一个壳,真的的代码都放在assets文件目录下面,它们把所有的Dex都合并成同一个secondary.dex.jar.xzs文件,通过大字典优化的压缩算法进行更高压缩率的压缩
但是这套方案似乎存在着某种问题:没有办法进行dex2oat或者dexopt的过程
而针对这个问题,Facebook工程师给出了他们的解答:通过ReDex中的oatmeal实现ODEX文件的生成
oatmeal的原理非常简单,和Tinker中对Zip文件的处理有异曲同工之妙,它会根据ODEX文件的格式,自己生成一个ODEX文件,它的生成结果跟解释执行的ODEX一样,内部是没有机器码的
相比正常的流程,这套方案可以避免fork进程所带来的大量时耗,把ODEX文件的生成时间控制在毫秒级以内
而有得必有失,在Android高手课中,前辈给出了这套方案的缺点:每个版本ODEX格式都有一些差异,oatmeal是需要分版本适配
但是回过头来想一想,其实对于MultiDex优化来说,我们需要兼容的ODEX文件版本其实也就是4.4版本了,这个问题自然迎刃而解,所以我觉得其实针对dexopt耗时这种情况下的优化,oatmeal自然是不二之选
但是由于笔者暂时对Dex文件结构、ReDex相关源码还不是特别熟悉,这里就不再进行方案的落地以及性能的测试了….
感悟
其实从本次对Tinker文件的处理,以及是oatmeal方案的认知,或者再追溯到之前笔者深入学习Android资源的系列中的微信资源混淆库的分析,其实我还是掌握一种解决问题的方式或者说思路,其实有时候,一些系统的流程可能是我们性能优化专项中最大的性能瓶颈,而对于文件结构的理解是可以帮助我们克服或者说绕过这些性能瓶颈,实际的例子数不胜数:
- Tinker中根据Zip文件的结构实现压缩率的迁移,从而规避了解压和压缩到来的时耗
- 移除无用资源、资源混淆、以及之前笔者的一文多渠道打包方案调研思考,可以通过对resources.arsc文件的理解帮助我们绕开反编译以及再次回编译的过程,进一步减少耗时
- V2签名的多渠道打包方案,通过对Zip文件的理解,可以绕开Android系统对apk的一些校验
- oatmeal,通过对Dex文件结构的理解,可以绕开fork进程所带来的一些时耗
笔者认为:学习方案、学习原理不只是停留在方案以及原理的层面,从更高的视野,回忆自己目睹过类似的设计,进行一些对比和学习,会有更为丰富的收获!
诚挚感谢前辈的努力: