Android资源学习(一)资源编译
# 前言
经历了一个多月的考试月,饱受了不能去探索技术道路的苦,今天考完最后一门课之后真的很激动的利用晚上的时间来给自己充充电,因为各种原因,笔者会写一系列和资源相关的文章,加深我对Android资源的理解和认识
# 资源编译关键流程
资源编译是Android apk构建的第一步,而这一步会生成R.java文件和resource.arsc和res
源码基于Android 9.0
aapt的可执行文件位于sdk的build-tools下,而源码则在frameworks\base\tools\aapt目录下。打包过程主要是调用了Resource.cpp下的buildResources()
frameworks\base\tools\aapt目录下的Main.cpp是aapt的入口,它会执行的handleCommand(Bundle* bundle)到Command.cpp下的doPackage(Bundle* bundle),经过一些初始化和检查后调用了我们要深入看的*buildResources(Bundle bundle, const sp
主要流程
- 解析AndroidManifest.xml
- 添加被引用资源包
- 收集资源文件
- 将收集的资源文件添加到资源表(ResourceTable)
- 编译value资源并添加到资源表(ResourceTable)
- 给bag资源分配ID
- 编译xml文件
- 生成资源符号
- 生成资源索引表
- 编译AndroidManifest.xml文件
- 生成R.java文件
- 写入apk
1. 解析AndroidManifest.xml
Resource.cpp-> buildResources
status_t buildResources(Bundle* bundle, const sp<AaptAssets>& assets, sp<ApkBuilder>& builder) {
sp<AaptGroup> androidManifestFile =
assets->getFiles().valueFor(String8("AndroidManifest.xml"));
if (androidManifestFile == NULL) {
fprintf(stderr, "ERROR: No AndroidManifest.xml file found.\n");
return UNKNOWN_ERROR;
}
status_t err = parsePackage(bundle, assets, androidManifestFile);
if (err != NO_ERROR) {
return err;
}
}
Resource.cpp-> parsePackage
static status_t parsePackage(Bundle* bundle, const sp<AaptAssets>& assets,
const sp<AaptGroup>& grp) {
// ......
sp<AaptFile> file = grp->getFiles().valueAt(0);
ResXMLTree block;
status_t err = parseXMLResource(file, &block);
if (err != NO_ERROR) {
return err;
}
// ......
size_t len;
ssize_t nameIndex = block.indexOfAttribute(NULL, "package");
assets->setPackage(String8(block.getAttributeStringValue(nameIndex, &len)));
// ......
}
在解析AndroidManifest.xml的步骤中主要是通过parsePackage函数执行
这个时候由于AndroidManifest.xml还没有转换成二进制的形式,所以只需要解析这个xml文件拿到想要的属性就可以
在这个解析工作中主要获取的是AndroidManifest.xml中与包相关的信息
2. 添加被引用资源包
Resource.cpp-> buildResources
status_t buildResources(Bundle* bundle, const sp<AaptAssets>& assets, sp<ApkBuilder>& builder) {
// ......
ResourceTable table(bundle, String16(assets->getPackage()), packageType);
err = table.addIncludedResources(bundle, assets);
}
根据上一步解析AndroidManifest.xml获取的包信息创建资源表(ResourceTable)
并且通过addIncludedResources函数添加依赖包
ResourceTable.cpp-> addIncludeResources
status_t ResourceTable::addIncludedResources(Bundle* bundle, const sp<AaptAssets>& assets) {
status_t err = assets->buildIncludedResources(bundle);
mAssets = assets;
mTypeIdOffset = findLargestTypeIdForPackage(assets->getIncludedResources(), mAssetsPackage);
const String8& featureAfter = bundle->getFeatureAfterPackage();
AssetManager featureAssetManager;
if (!featureAssetManager.addAssetPath(featureAfter, NULL)) {
return UNKNOWN_ERROR;
}
const ResTable& featureTable = featureAssetManager.getResources(false);
mTypeIdOffset = std::max(mTypeIdOffset,
findLargestTypeIdForPackage(featureTable, mAssetsPackage));
return NO_ERROR;
}
Android系统定义了一套通用资源,这些资源可以被应用程序引用,这一个步骤的目的就是为了把这套通用的资源添加到我们的应用程序中
buildIncludedResource函数的主要作用就是从main.cpp中携带过来bundle构建引用资源包,而其实Android系统对应用程序提供通用资源的方式依然是apk,只不过,这个apk的解析工作在main.cpp中执行,然后把一些数据储存在bundle中,然后在此刻再延时添加引用资源而已
而应用程序调用引用资源包的资源的方式便是资源ID,然后只需要用package ID进行区分就可以了(0x01)
3. 收集资源文件
Resource.cpp-> buildResources
status_t buildResources(Bundle* bundle, const sp<AaptAssets>& assets, sp<ApkBuilder>& builder) {
KeyedVector<String8, sp<ResourceTypeSet> > *resources =
new KeyedVector<String8, sp<ResourceTypeSet> >;
collect_files(assets, resources);
}
Resource.cpp-> collect_files
static void collect_files(const sp<AaptAssets>& ass,
KeyedVector<String8, sp<ResourceTypeSet>>* resources) {
const Vector<sp<AaptDir> >& dirs = ass->resDirs();
int N = dirs.size();
for (int i=0; i<N; i++) {
const sp<AaptDir>& d = dirs.itemAt(i);
collect_files(d, resources);
ass->removeDir(d->getLeaf());
}
}
收集资源文件的方法就是先创建一个KeyedVector用来存放收集的资源,而ResourceTypeSet本来也是一个K-V容器,所以储存资源文件的数据结构就是KeyedVector<String8, KeyedVector<String8, AdaptGroup»,然后因为AdaptGroup是维度信息和文件的DefaultKeyedVector
所以资源存储容器得最终结构:
KeyedVector<类型名称,KeyedVector<资源名称,KeyedVector<维度信息对象,资源文件»>
Resource.cpp-> buildResources
sp<AaptAssets> current = assets->getOverlay();
while(current.get()) {
KeyedVector<String8, sp<ResourceTypeSet> > *resources =
new KeyedVector<String8, sp<ResourceTypeSet> >;
current->setResources(resources);
collect_files(current, resources);
current = current->getOverlay();
}
if (!applyFileOverlay(bundle, assets, &drawables, "drawable") ||
!applyFileOverlay(bundle, assets, &layouts, "layout") ||
!applyFileOverlay(bundle, assets, &anims, "anim") ||
!applyFileOverlay(bundle, assets, &animators, "animator") ||
!applyFileOverlay(bundle, assets, &interpolators, "interpolator") ||
!applyFileOverlay(bundle, assets, &transitions, "transition") ||
!applyFileOverlay(bundle, assets, &xmls, "xml") ||
!applyFileOverlay(bundle, assets, &raws, "raw") ||
!applyFileOverlay(bundle, assets, &colors, "color") ||
!applyFileOverlay(bundle, assets, &menus, "menu") ||
!applyFileOverlay(bundle, assets, &fonts, "font") ||
!applyFileOverlay(bundle, assets, &mipmaps, "mipmap")) {
return UNKNOWN_ERROR;
}
处理overlay(重叠包,如果指定的重叠包有和当前编译包重名的资源,则使用重叠包的)
4. 将收集到的资源文件加到资源表(ResourceTable)
Resource.cpp-> buildResources
// ......
if (layouts != NULL) {
err = makeFileResources(bundle, assets, &table, layouts, "layout");
if (err != NO_ERROR) {
hasErrors = true;
}
}
if (anims != NULL) {
err = makeFileResources(bundle, assets, &table, anims, "anim");
if (err != NO_ERROR) {
hasErrors = true;
}
}
//.......
Resource.cpp-> makeFileResources
static status_t makeFileResources(Bundle* bundle, const sp<AaptAssets>& assets,
ResourceTable* table,
const sp<ResourceTypeSet>& set,
const char* resType) {
ResourceDirIterator it(set, String8(resType));
status_t result = table->addEntry(SourcePos(it.getPath(), 0),
String16(assets->getPackage()),
type16,
baseName,
String16(resPath),
NULL,
&it.getParams());
// ......
}
在把收集到的资源文件添加到资源表(ResourceTable)中流程中,主要关注点是与ResourceTable相关的逻辑,就是资源如果从集合中拿出来添加到table中
收集资源的集合会转变成一个ResourceDirIterator
addEntry函数的最后一个参数就是Restable_Config,也就是我们熟知的arsc中跟在typeSpec后面的type,因为在转变成ResourceDirIterator过程中已经筛选出typeSpec,所以只需要找到对应的type,把Entry添加进去就完成了
5. 编译values资源并添加到资源表
在上一步添加过程中,其实并没有对values资源进行处理,因为values比较特殊,需要经过编译之后,才能添加到资源表中
Resource.cpp-> buildResources
status_t buildResources(Bundle* bundle, const sp<AaptAssets>& assets, sp<ApkBuilder>& builder) {
// .......
current = assets;
while(current.get()) {
KeyedVector<String8, sp<ResourceTypeSet> > *resources =
current->getResources();
ssize_t index = resources->indexOfKey(String8("values"));
if (index >= 0) {
ResourceDirIterator it(resources->valueAt(index), String8("values"));
ssize_t res;
while ((res=it.next()) == NO_ERROR) {
const sp<AaptFile>& file = it.getFile();
res = compileResourceFile(bundle, assets, file, it.getParams(),
(current!=assets), &table);
}
}
current = current->getOverlay();
}
}
在这个步骤其实就是遍历values资源,compileResourceFile函数定在ResourceTable.cpp中
主要的工作就是对文本xml的解析并添加到ResouceTable中
所以其实values类的资源是不会存在Resource.cpp的KeyedVector中的
6. 给bag资源分配id
Resource.cpp-> buildResources
if (table.hasResources()) {
err = table.assignResourceIds();
if (err < NO_ERROR) {
return err;
}
}
使用ResourceTable中的assignResourceIds函数给bag资源分配id
在继续编译其他资源之前,需要先给bag资源(attrs,比如orientation这种属性的取值范围定义的子元素)分配id,因为其他资源可能对它们有引用
7. 编译xml资源文件
xml资源文件的编译需要放在这一步去做,主要是因为xml资源文件会依赖前面编译的资源,所以需要先把其他资源的编译完成
Resource.cpp-> buildResources
err = compileXmlFile(bundle, assets, String16(it.getBaseName()),
it.getFile(), &table, xmlFlags);
ResourceTable.cpp-> comlipXmlFile
status_t compileXmlFile(const Bundle* bundle,
const sp<AaptAssets>& assets,
const String16& resourceName,
const sp<AaptFile>& target,
ResourceTable* table,
int options)
{
sp<XMLNode> root = XMLNode::parse(target);
return compileXmlFile(bundle, assets, resourceName, root, target, table, options);
}
ResourceTable.cpp-> comilpXmlFile
status_t compileXmlFile(const Bundle* bundle,
const sp<AaptAssets>& assets,
const String16& resourceName,
const sp<XMLNode>& root,
const sp<AaptFile>& target,
ResourceTable* table,
int options) {
// ......
bool hasErrors = false;
if ((options&XML_COMPILE_ASSIGN_ATTRIBUTE_IDS) != 0) {
status_t err = root->assignResourceIds(assets, table);
}
if ((options&XML_COMPILE_PARSE_VALUES) != 0) {
status_t err = root->parseValues(assets, table);
}
status_t err = root->flatten(target,
(options&XML_COMPILE_STRIP_COMMENTS) != 0,
(options&XML_COMPILE_STRIP_RAW_VALUES) != 0);
target->setCompressionMethod(ZipEntry::kCompressDeflated);
return err;
}
xml文件的编译主要的几个步骤:
- parse 解析xml文件
- assignResourceIds 赋予属性名称ID
- parseValues 解析属性值
- flatten 序列化成二进制形式
ResourceTable-> parse
解析xml生成XMLNode对象,结构为:
–mElementName,表示Xml元素标签
–mChars,表示Xml元素的文本内容
–mAttributes,表示Xml元素的属性列表
–mChildren,表示Xml元素的子元素
XMLNode-> assignResourceIds
status_t XMLNode::assignResourceIds(const sp<AaptAssets>& assets,
const ResourceTable* table) {
if (getType() == TYPE_ELEMENT) {
String16 attr("attr");
const char* errorMsg;
const size_t N = mAttributes.size();
for (size_t i=0; i<N; i++) {
// 遍历xml的标签
const attribute_entry& e = mAttributes.itemAt(i);
// 获取包信息
String16 pkg(getNamespaceResourcePackage(String16(assets->getPackage()), e.ns, &nsIsPublic));
uint32_t res = table != NULL
? table->getResId(e.name, &attr, &pkg, &errorMsg, nsIsPublic)
: assets->getIncludedResources().
identifierForName(e.name.string(), e.name.size(),
attr.string(), attr.size(),
pkg.string(), pkg.size());
if (res != 0) {
setAttributeResID(i, res);
}
}
}
// 递归遍历子标签
// ......
这一步会给xml的每一个属性名赋予一个资源ID
对于系统资源包里面定义的属性名,Android资源打包工具,首先是要在系统资源包里面找到这些名称所对应的资源ID,然后再进行XMLNode中ID赋值
而从代码中可以看出其实在resource.arsc中attr类型的资源其实就是xml的属性名编译的产物
XMLNode-> parseValues
这一步会xml标签的属性值进行解析
而为什么在此之前要去给xml的每一个属性值赋予一个资源ID,是因为在这一步,需要根据这个ID找到元数据,从而进行结果解析
而对于引用类型的属性值,比如我们平时经常写的id = @+id/xxxxx,会在这个阶段中解析,这里的+的含义就是如果在指定的包里面找不到这个引用的话,那么就会在该包里面创建一个新的,而这些生成的资源类型其实就是id类型的,而在定义id的时候,其实可以定义id的包@+[package:]id/xxxxx,而像我们日常的没有定义package写法会自定添加到当前编译的包中,而其实大部分时候也只有一个package
XMLNode-> flatten
status_t XMLNode::flatten(const sp<AaptFile>& dest,
bool stripComments, bool stripRawValues) const {
StringPool strings(mUTF8);
Vector<uint32_t> resids;
// 首先只收集具有
// 分配给他们的资源ID。 这样可以确保资源ID
// 数组很紧凑,可以更轻松地处理属性名称
// 在不同的名称空间中(因此具有不同的资源ID)
collect_resid_strings(&strings, &resids);
// 接下来收集所有剩余字符串
collect_strings(&strings, &resids, stripComments, stripRawValues);
// 创建常量池Block
sp<AaptFile> stringPool = strings.createStringBlock();
// 创建xml header并初始化
ResXMLTree_header header;
memset(&header, 0, sizeof(header));
header.header.type = htods(RES_XML_TYPE);
header.header.headerSize = htods(sizeof(header));
// 计算当前的写入位置,这里就是初始位置
const size_t basePos = dest->getSize();
// 往目标文件写入xml header
dest->writeData(&header, sizeof(header));
// 往目标文件写入常量池
dest->writeData(stringPool->getData(), stringPool->getSize());
// 如果有资源ID,写下它们
if (resids.size() > 0) {
const size_t resIdsPos = dest->getSize();
const size_t resIdsSize =
sizeof(ResChunk_header)+(sizeof(uint32_t)*resids.size());
// 创建chunk_header并初始化,用于承载resId
ResChunk_header* idsHeader = (ResChunk_header*)
(((const uint8_t*)dest->editData(resIdsPos+resIdsSize))+resIdsPos);
idsHeader->type = htods(RES_XML_RESOURCE_MAP_TYPE);
idsHeader->headerSize = htods(sizeof(*idsHeader));
idsHeader->size = htodl(resIdsSize);
uint32_t* ids = (uint32_t*)(idsHeader+1);
for (size_t i=0; i<resids.size(); i++) {
*ids++ = htodl(resids[i]);
}
}
// 压平xml文件
flatten_node(strings, dest, stripComments, stripRawValues);
void* data = dest->editData();
ResXMLTree_header* hd = (ResXMLTree_header*)(((uint8_t*)data)+basePos);
hd->header.size = htodl(dest->getSize()-basePos);
return NO_ERROR;
}
方法的执行流程为:
- 收集有资源ID的属性的名称字符串
- 收集其它字符串
- 写入xml header
- 写入字符串资源池
- 写入资源ID
- 压平xml文件
XMLNode-> flatten_node
压扁xml文件会形成二进制形式的xml文件,一般会分为2种:
一种是像我们layout的那种xml
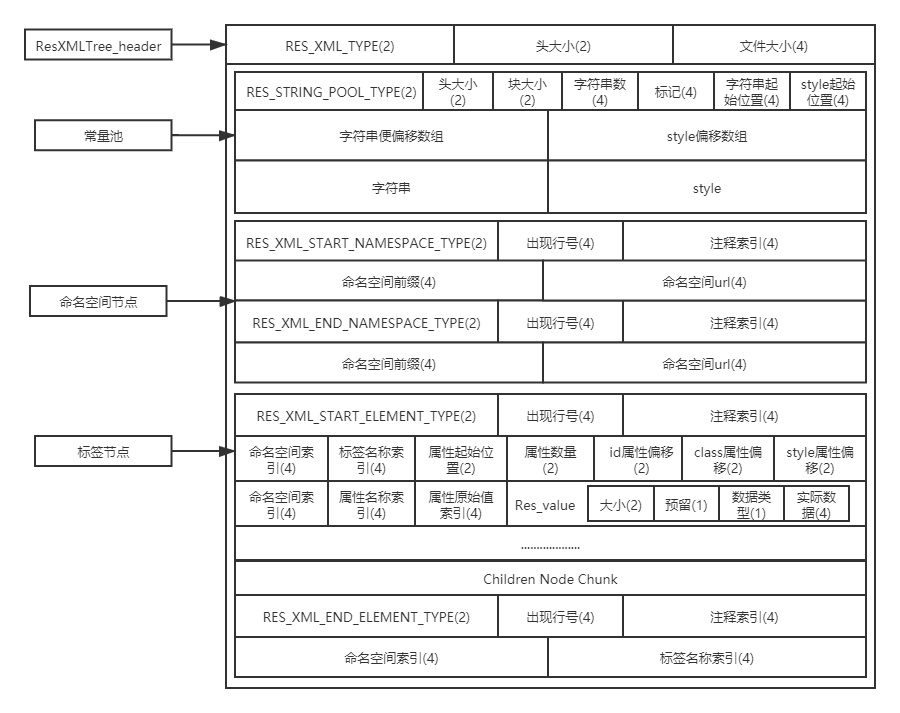
另一种则是用于承载数据的xml,如
<item> Cc1over </item>

8. 生成资源符号
这一步是为了生成R.java文件所准备的,因为在之前的操作中会把收集到的资源添加到KeyedVector中然后转添加到ResourceTable中,所以其实来的这一步ResoureTable包含了所有的资源,包含KeyedVector没有的bag和values,所以在这个阶段需要操作的是ResourceTable
生成资源符号的逻辑为:
- 遍历每一个Package
- 遍历Packgae中的每一个Type
- 遍历Type中的所有Entry
- 取出Entry名称
- 根据出现次序计算资源ID
注意点:ResID为4个字节,PTEE,高字节表示Package ID,次高字节表示Type ID,低两字节表示Entry ID,而Entry ID就是根绝Entry在Type中出现顺序决定的
9. 生成资源索引表
经历了上面的各个收集和编译操作,其实所有的资源都保存在ResourceTable中,所以resource.arsc资源索引表的生成,与二进制xml文件的生成类似利用的也是flatten生成的
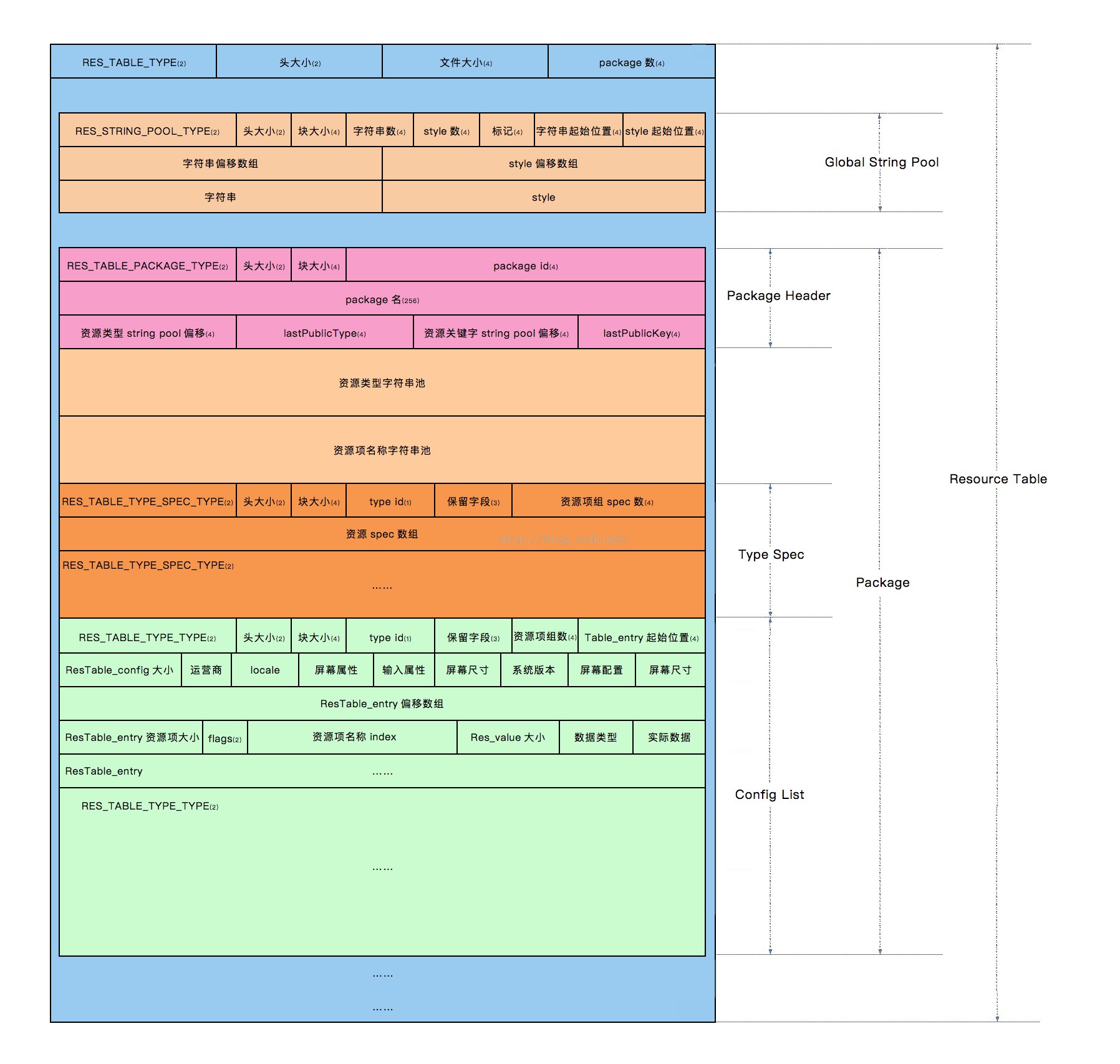
注意点
-
在Android资源中,有一种资源类型称为Public,它们一般是定义在res/values/public.xml文件中
-
这个public.xml用来告诉Android资源打包工具aapt,将类型为string的资源string3的ID固定为0x7f040001。为什么需要将某一个资源项的ID固定下来呢?一般来说,当我们将自己定义的资源导出来给第三方应用程序使用时,为了保证以后修改这些导出资源时,仍然保证第三方应用程序的兼容性,就需要给那些导出资源一个固定的资源ID
-
每当Android资源打包工具aapt重新编译被修改过的资源时,都会重新给这些资源赋予ID,这就可能会造成同一个资源项在两次不同的编译中被赋予不同的ID。这种情况就会给第三方应用程序程序带来麻烦,因为后者一般是假设一个ID对应的永远是同一个资源的。因此,当我们将自己定义的资源导出来给第三方应用程序使用时,就需要通过public.xml文件将导出来的资源的ID固定下来
10. 编译AndroidManifest.xml文件
AndroidManifest.xml文件的编译放在这个位置,其实也是因为AndroidManifest需要引用到上面的产物,而AndroidManifest.xml的编译工作和普通的xml文件类似,都是调用compileXmlFile函数编译成二进制的形式
而与其他xml文件编译不一致的是,aapt会检查AndroidManifest.xml的有效性,例如,验证AndroidManifest.xml的根节点mainfest必须定义有android:package属性
11. 生成R.java文件
在第8步生成资源符号中,已经将所有的资源项及其所对应的资源ID都收集起来了 ,所以,这里只要将直接将它们写入到指定的R.java文件去就可以了
12. 写入apk
把资源编译生成的产物添加到apk中,产物包括:
- assets目录
- res目录,但是不包括res/values目录,因为res/values目录下的资源文件已经写入resource.arsc中了
- 资源项索引文件resources.arsc
参考资料: